
Trace = sign of the past, inscription of a past event or process
Annotation - trace of a scholarly reading activity

Page of the Codex Oxoniensis Clarkianus 39 (Clarke Plato). Dialogue Gorgias. Public Domain


Output from the performance "Le Déparleur" (Patrick Bernier et Olive Martin). Personal photograph - Olivier Aubert, CC BY-SA 4.0



 Social network traces Source
Social network traces Source
Aggregated social network traces Source
Netflix part of Digital Advertising Alliance
In 2016:
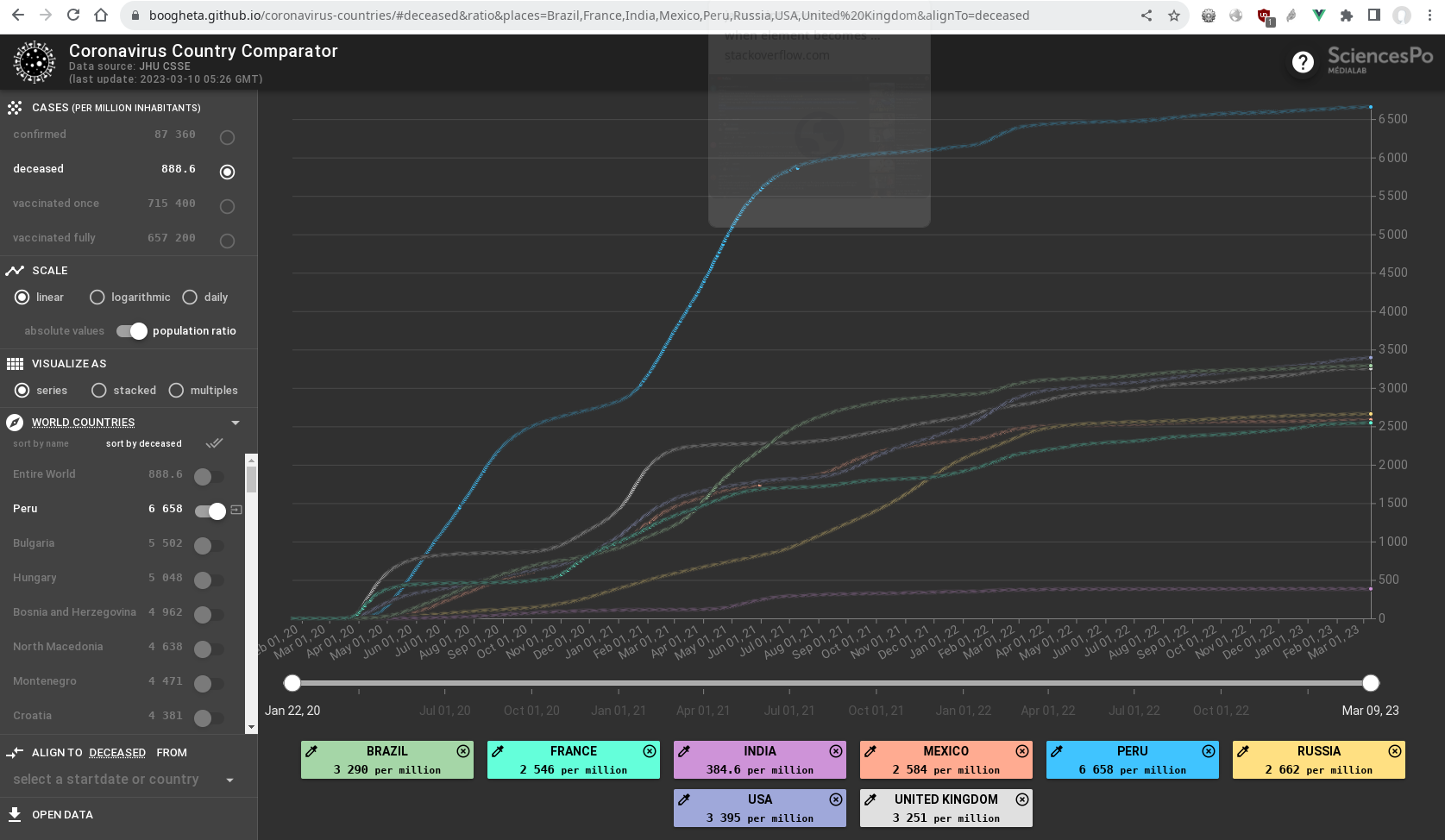
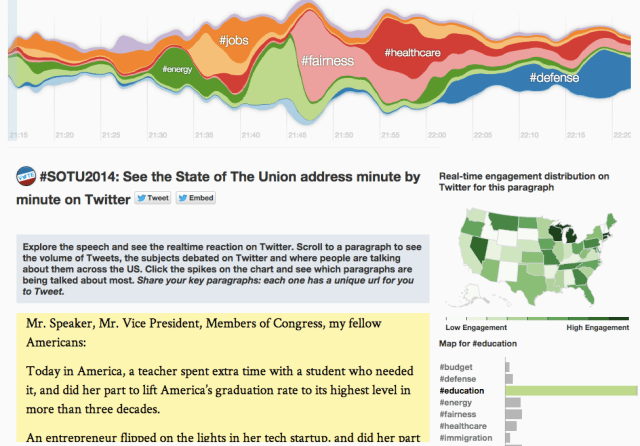
Coronavirus Country Comparator - Source
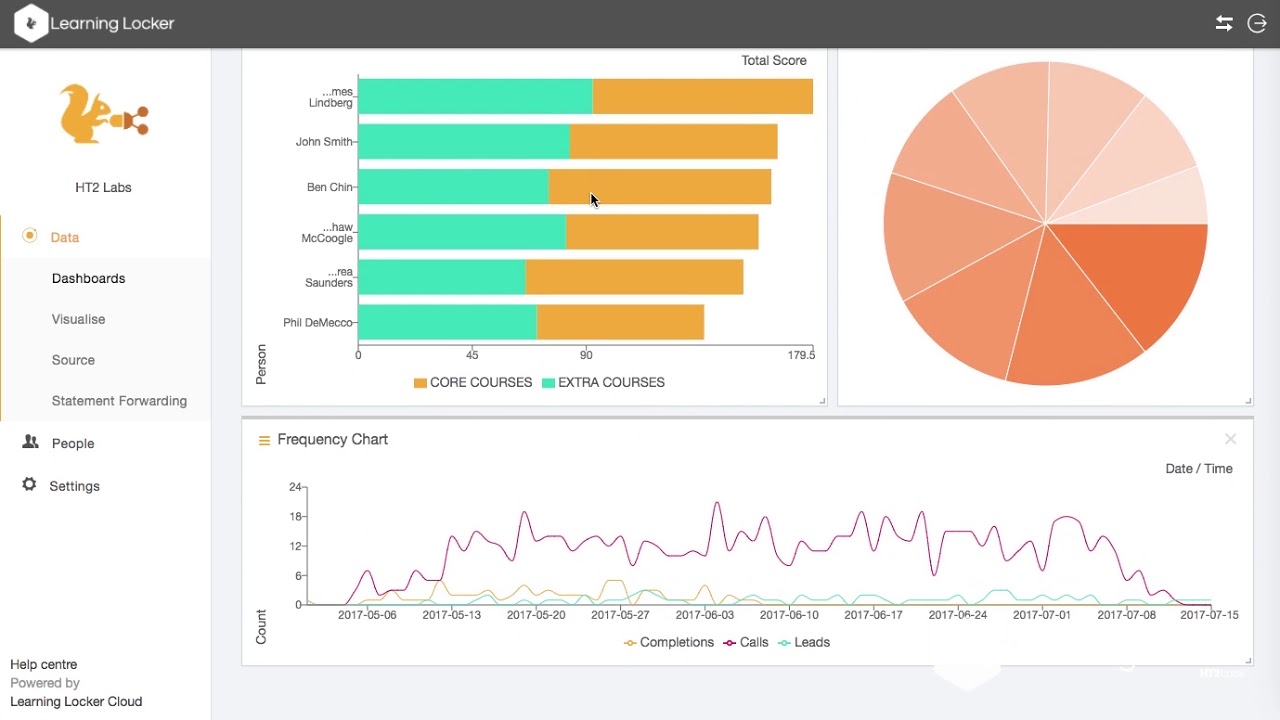
Learning Analytics dashboard Source
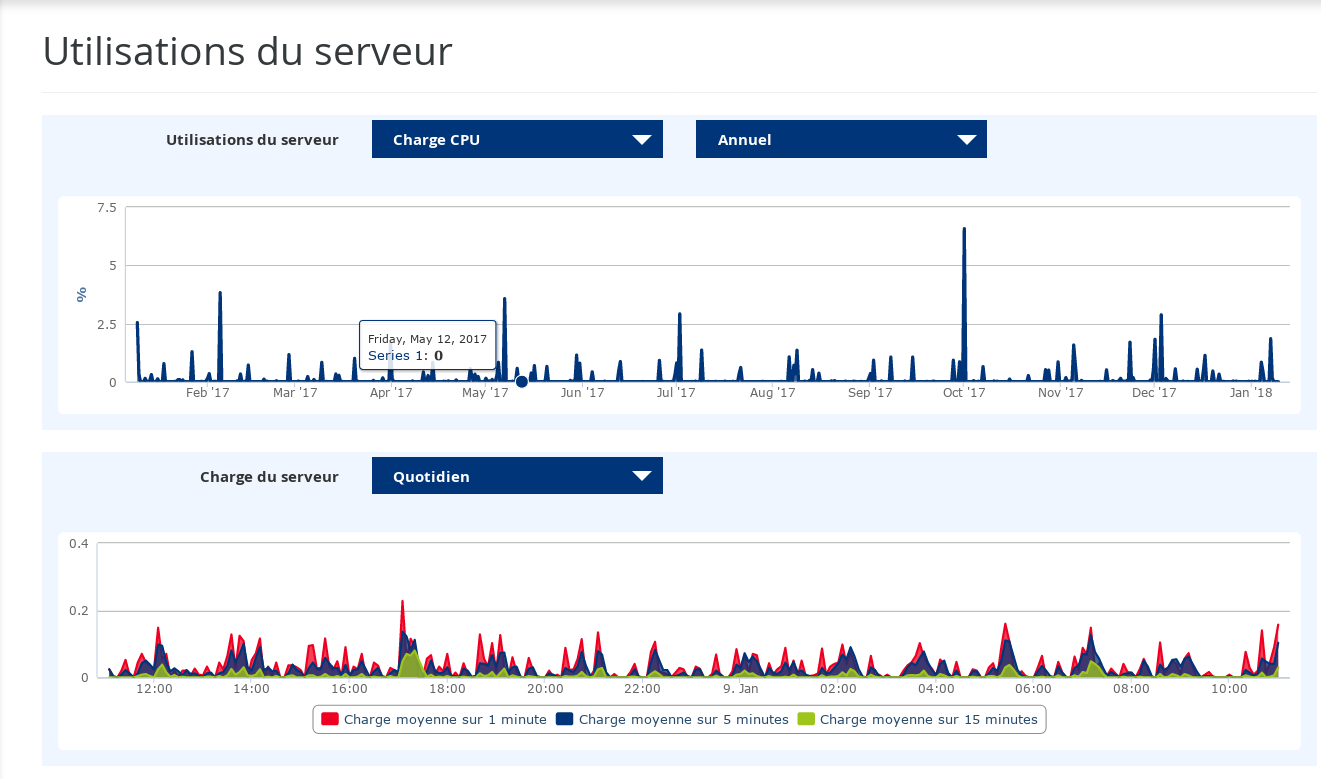
Access logs (offices, servers), sensor logs (health, linky, IOT…)
Issues in
Many types of traces. Here we will focus on:
but there are also
Wooclap survey time!
General Data Protection Regulation (GDPR) / Règlement Général sur la Protection des Données (RGPD)
Facebook €1200 million (2023) - transfer of personal data to the US
(see GDPR enforcement tracker)
01/11/2023 : EDPB Urgent Binding Decision on processing of personal data for behavioural advertising by Meta
Meta interdit de faire de la publicité ciblée (french)
See EDPB website for more decisions
Learning analytics is the measurement, collection, analysis and reporting of data about learners and their contexts, for purposes of understanding and optimizing learning and the environments in which it occurs. Source
Interdisciplinary domain (data science, pedagogy, social sciences)
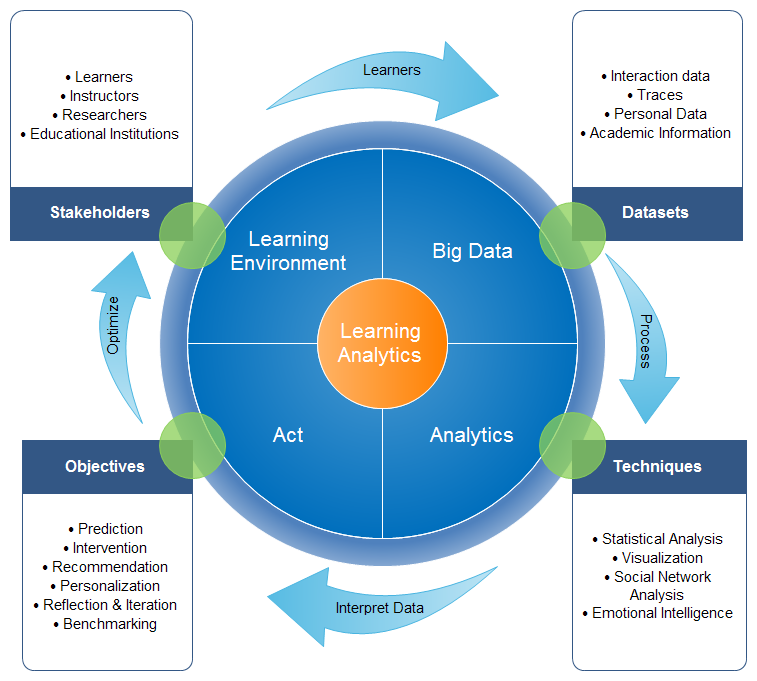
Issue: traces are generated on a variety of platforms
As mentioned before, ethics is a consideration to always keep first in mind.
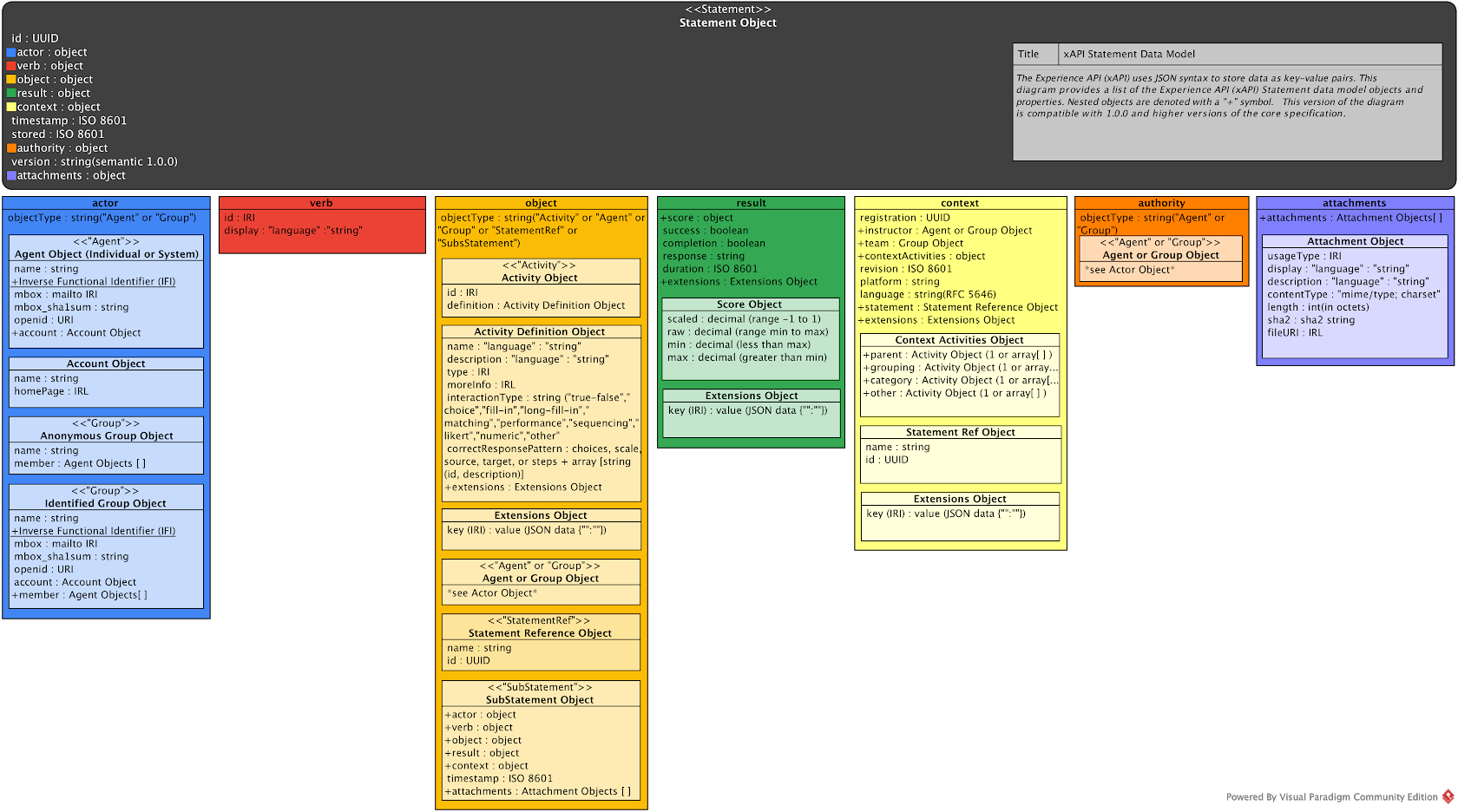
ExperienceAPI website - Reference spec
Activity events are recorded as Statements
Statement = (timestamp, actor, verb, object) [+ context] [+ result] [+ stored timestamp] [+ authority]
{ "timestamp: "2023-10-15T11:30:02.598441+01:00",
"actor": { "name": "Olivier Aubert",
"mbox": "mailto:contact@olivieraubert.net" },
"verb": { "id": "https://activitystrea.ms/schema/1.0/present",
"display": { "en-US": "presented" } },
"object": { "id": "https://olivieraubert.net/cours/gcn_stockage_traces",
"definition": {
"name": "Traces - issues, capture, storage, manipulation",
"type": "https://adlnet.gov/expapi/activities/lesson"
}
"context": { "language": "fr",
"extensions": {
"https://www.polytech.univ-nantes.fr/xapi/polytechRoom": "D004"
}
},
"stored": "2023-10-12T11:30:03.954814+01:00",
}
Identified by at most ONE of mbox, mbox_sha1sum, openid, account (homepage, name)
{
"name": "Olivier Aubert",
"mbox": "mailto:contact@olivieraubert.net"
}
or
{ {
"name": "Olivier Aubert", "name": "Olivier Aubert",
"account": { "account": {
"homePage": "https://orcid.org/", "homePage": "https://madoc.univ-nantes.fr/",
"name": "0000-0001-8204-1567" "name": "aubert-o"
} }
} }
Agent + specify objectType and member list.
{
mbox: "mailto:info@tincanapi.com",
name: "Info at TinCanAPI.com",
objectType: "Group",
member: [
{
mbox_sha1sum: "48010dcee68e9f9f4af7ff57569550e8b506a88d",
mbox_sha1sum: "9023723cde2d3efc5810dcee68e9f9f4af7ff575"
},
…
}
URI + display string
{
"id": "http://adlnet.gov/expapi/verbs/experienced",
"display": {
"en-US": "experienced"
}
}
From xAPI vocabulary & profile index (common vocabularies), many common ones come from ActivityStreams W3C recommendation.
In particular, CMI5 defines (not only) a standard profile for learning content.
Normally an activity, but can also be a person, group or even another statement.
{ "id": "https://olivieraubert.net/cours/gcn_stockage_traces",
"definition": {
"name": "Traces - issues, capture, storage, manipulation",
"type": "http://adlnet.gov/expapi/activities/lesson"
}
}
or
{ "objectType": "Agent",
"mbox":"mailto:test@example.com"
}
Additional information about the activity context
"context": { "language": "fr",
"extensions": {
"http://www.polytech.univ-nantes.fr/xapi/polytechRoom": "D004"
}
}
Representation of a measured outcome.
score (Object): score of the Agent in relation to success/quality of the experience.success (Boolean): Indicates whether or not the attempt on the Activity was successful.completion (Boolean): Indicates whether or not the Activity was completed.response (String): A response appropriately formatted for the given Activity.duration (String): Period of time over which the Statement occurred.object, context and result can feature an “extensions” list"context": { "language": "fr",
"extensions": {
"http://www.polytech.univ-nantes.fr/xapi/polytechRoom": "D004"
}
}
4 REST APIs (last 3: Document APIs)
Call (source)
POST https://v2.learninglocker.net/v1/data/xAPI/activities/state
URL Parameters
activityId:http://www.example.com/activities/1
stateId:http://www.example.com/states/1
agent:{“objectType”: “Agent”, “name”: “John Smith”,
“account”:{“name”: “123”,
“homePage”: “http://www.example.com/users/”}}
Headers
Authorization:Basic YOUR_BASIC_AUTH X-Experience-API-Version:1.0.0 Content-Type:application/json
Body
{
“favourite”: “It’s a Wonderful Life”,
“cheesiest”: “Mars Attacks”
}
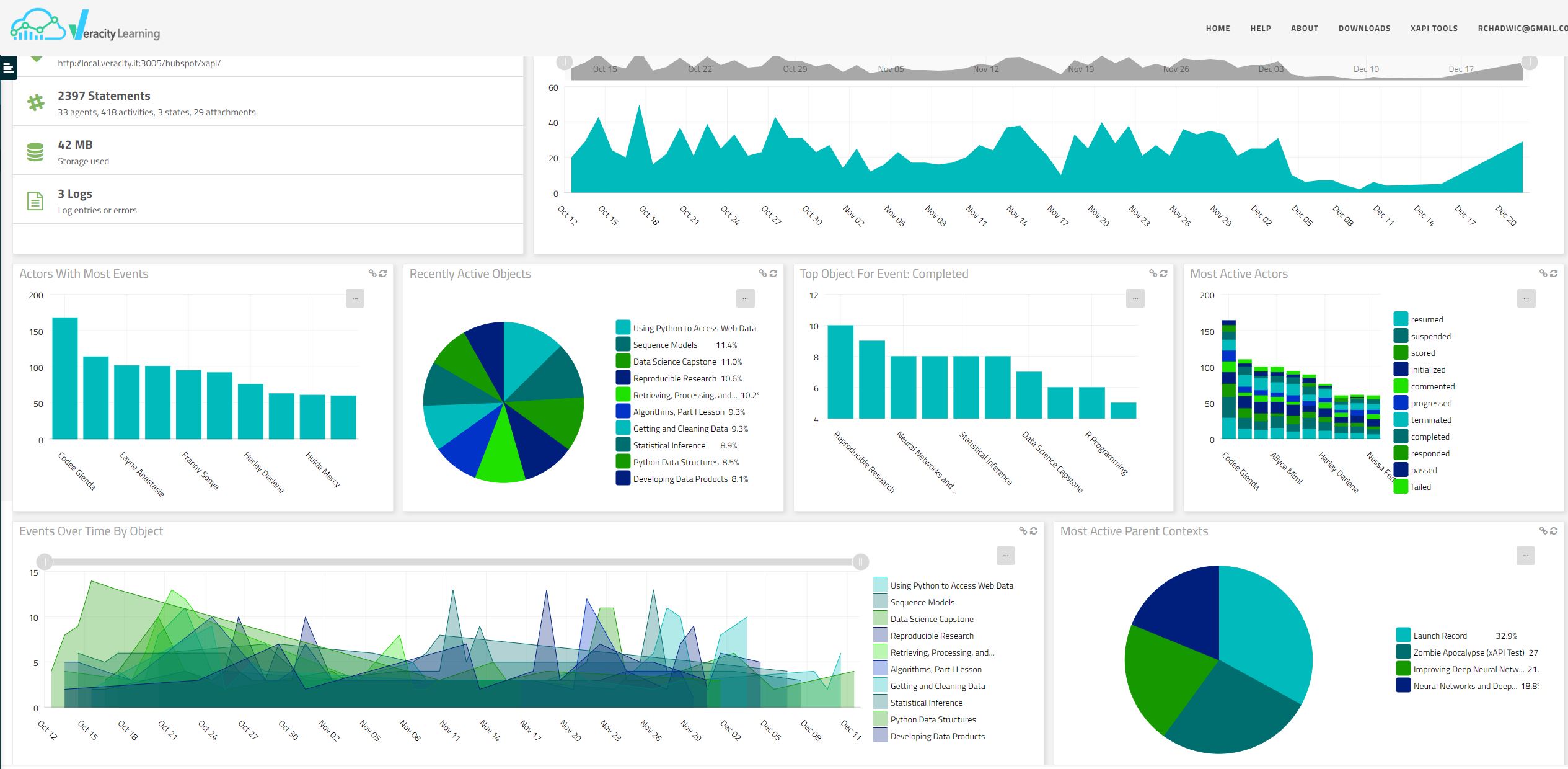 From Veracity
From Veracity
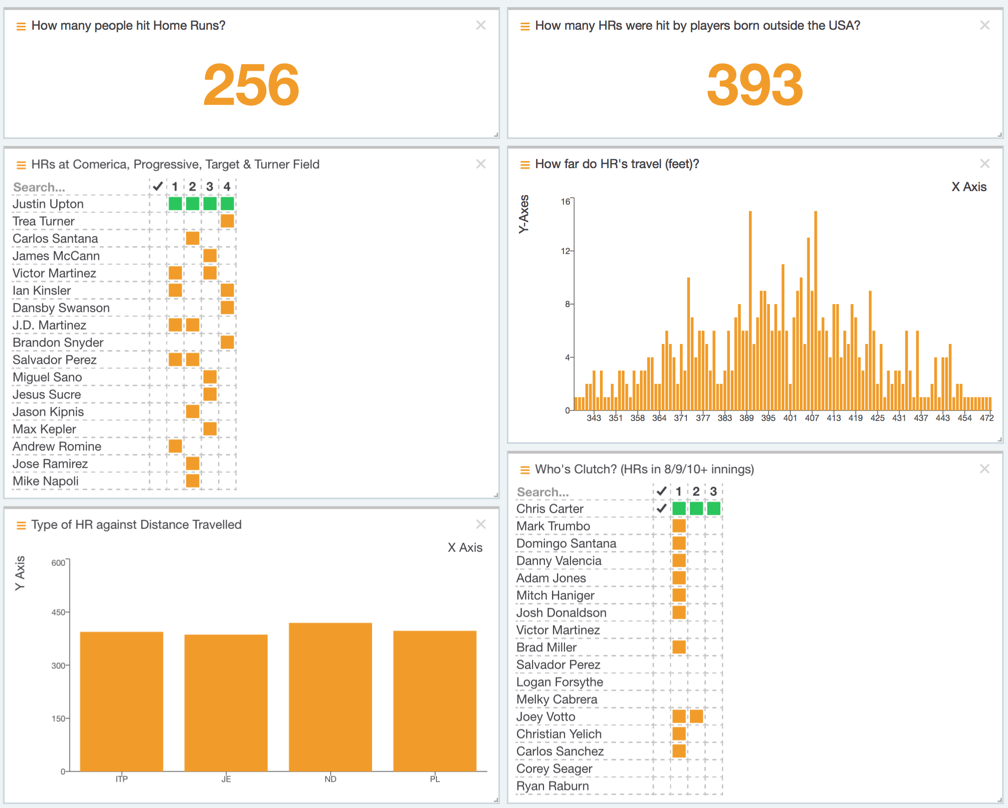
eFiL project
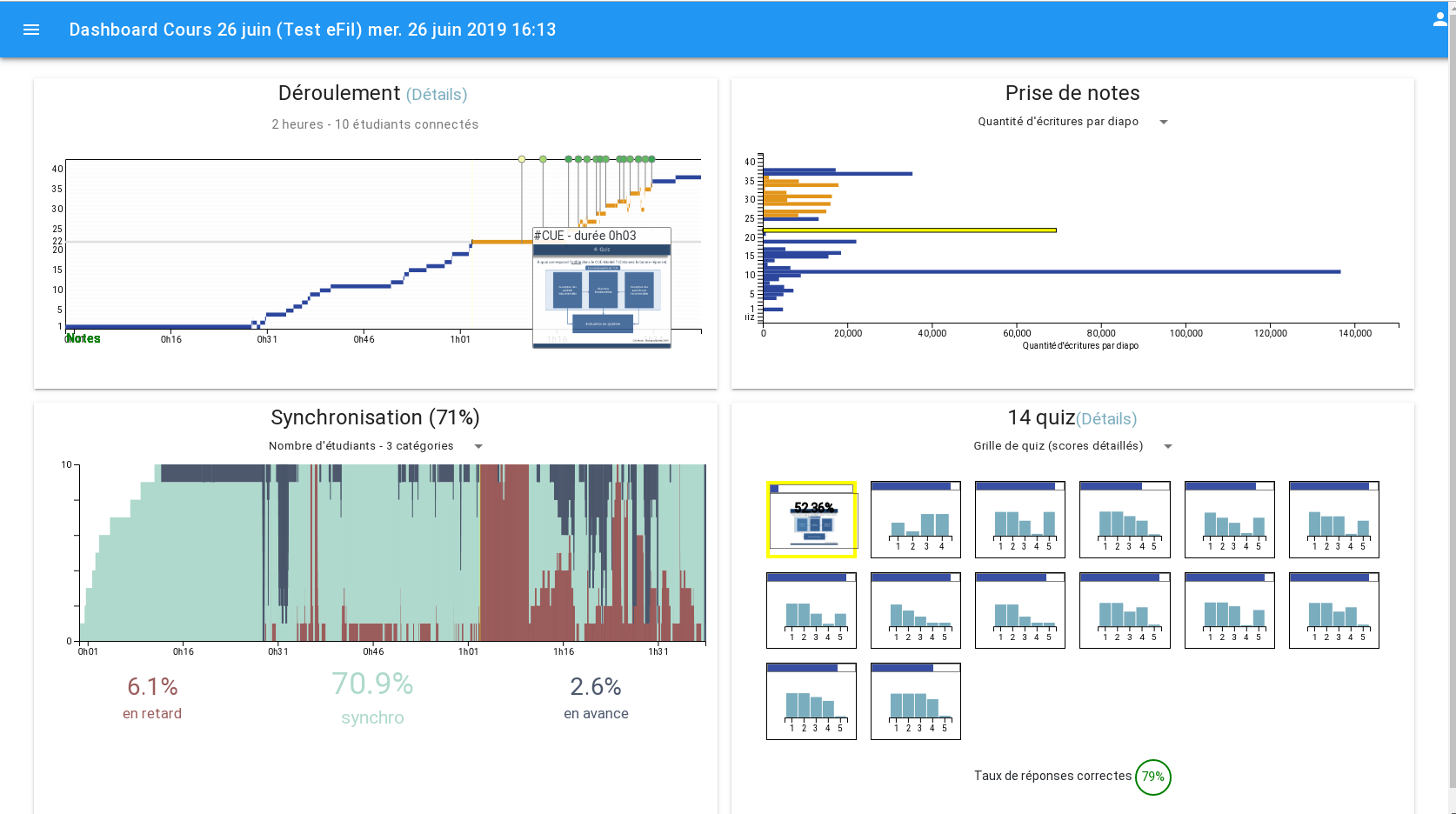
Source: eFiL
A Time Series is
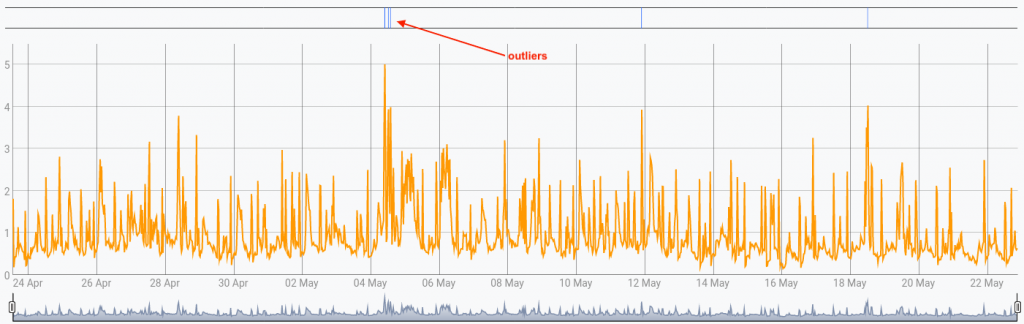
Source: Analyze your electrical consumption using Warp10
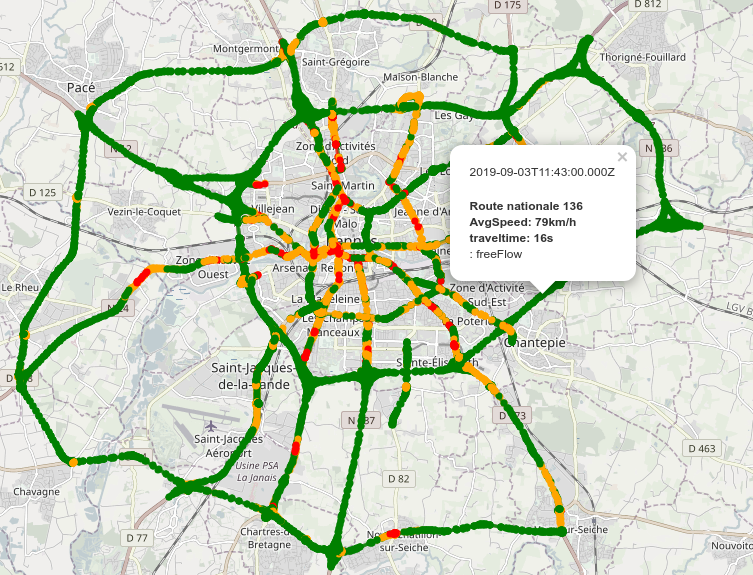
Source: Traffic data for Smart Cities
Time series data can be defined as:
Time Series can be stored in conventional databases (relational) - see "Point Based data model" - slide 41 of Temporal Databases lecture
| series_id | timestamp | value |
| s01 | 00:50:37 | 2.56 |
| s02 | 00:53:53 | 3.12 |
| s01 | 00:56:52 | 4.42 |
| s02 | 01:00:16 | 3.23 |
| s01 | 01:03:32 | 5.20 |
| s01 | 01:06:24 | 6.20 |
⇒ need for specialized time series databases
Warm vs cold data
Storage/archival of cold data/timeseries.
Example from Time Series et santé: datalogger médical 100hz, retour d'expérience après un an:
Global categories of databases:
A TSDB system is
Based on these characteristics
One row/doc per time period, columns are samples
| series_id | start | t+1 | t+2 | t+3 | … |
| s01 | 00:00:10 | 2.56 | 3.12 | 4.42 | … |
| s02 | 00:00:10 | 4.12 | 5.12 | 6.12 | … |
| s01 | 00:00:20 | 4.23 | 4.44 | 4.76 | … |
…
One row/doc per time period, completed lines are stored as BLOB.
| series_id | start | t+1 | t+2 | t+3 | … | compressed |
| s01 | 00:00:10 | … | {…} | |||
| s02 | 00:00:10 | … | {…} | |||
| s01 | 00:00:20 | 4.23 | 4.44 | … |
…
Usually with memory cache.
| series_id | start | data |
| s01 | 00:00:10 | {…} |
| s02 | 00:00:10 | {…} |
| s01 | 00:00:20 | {…} |
…
See also list of TSDB
Using Line Protocol:
<measurement>[,<tag-key>=<tag-value>...] \ <field-key>=<field-value>[,<field2-key>=<field2-value>...] \ [unix-nano-timestamp]
Example:
cpu,host=serverA,region=us_west value=0.64 payment,device=mobile,product=Notepad,method=credit billed=33,licenses=3 1434067467100293230 stock,symbol=AAPL bid=127.46,ask=127.48 temperature,machine=unit42,type=assembly external=25,internal=37 1434067467000000000
SQL-inspired - Example:
SELECT MEAN("water_level")
FROM "h2o_feet"
WHERE "location"='santa_monica'
AND time >= '2015-09-18T21:30:00Z'
AND time <= now()
GROUP BY time(1h) fill(none)
// Sample query from(bucket: "noaa") |> range(start: 2015-09-18, end: 2015-10-18) |> filter(fn: (r) => r._measurement == "h2o_feet") |> filter(fn: (r) => r.location == "santa_monica") |> filter(fn: (r) => r._field == "water_level") |> aggregateWindow(every: 1h, fn: mean ) |> yield(name: "Mean")
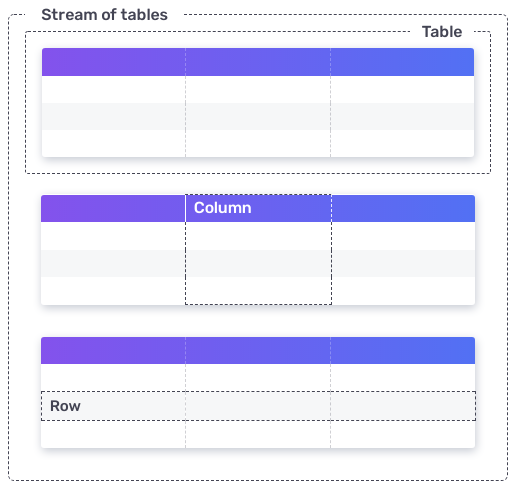
Flux functions (aggregations, selectors) use stream of tables as input and output
Platform for collecting, storing, graphing, and alerting on time series data
POST /api/v0/update HTTP/1.1
Host: host
X-Warp10-Token: TOKEN
Content-Type: text/plain
1380475081000000// foo{label0=val0,label1=val1} 123
/48.0:-4.5/ bar{label0=val0} 3.14
1380475081123456/45.0:-0.01/10000000 foobar{label1=val1} T
'TOKEN_READ' 'token' STORE // Storing token
[ $token ‘consumption’ {} NOW 1 h ] FETCH // Fetch all values from now to 1 hour ago
[ SWAP bucketizer.max 0 1 m 0 ] BUCKETIZE // Get max value for each minute
[ SWAP [ 'room' ] reducer.sum ] REDUCE // Aggregate all consumptions by room
[ SWAP mapper.rate 1 0 0 ] MAP // Consumption being a counter, compute the rate
NeuralForecast - collection of neural forecasting models
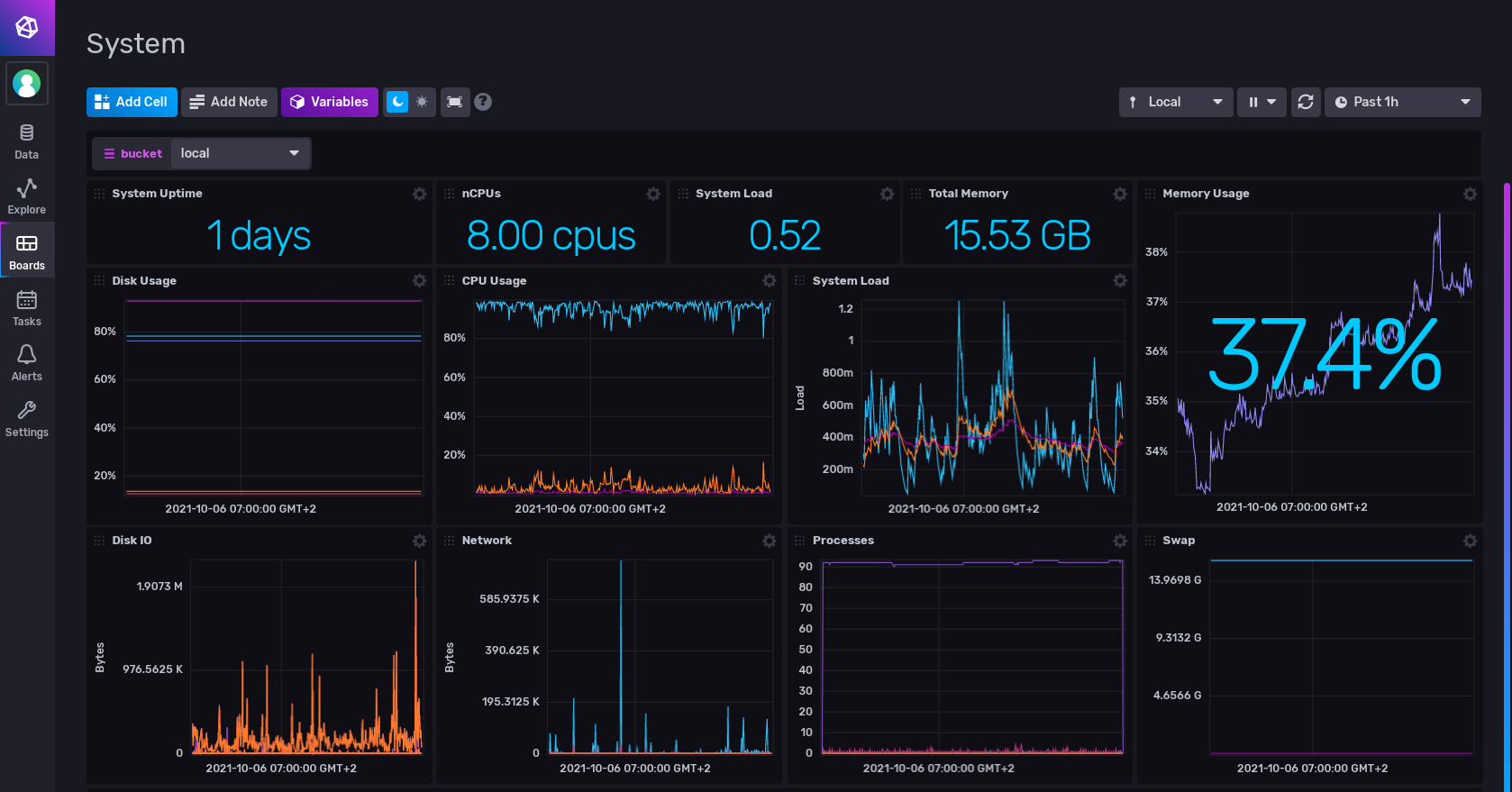
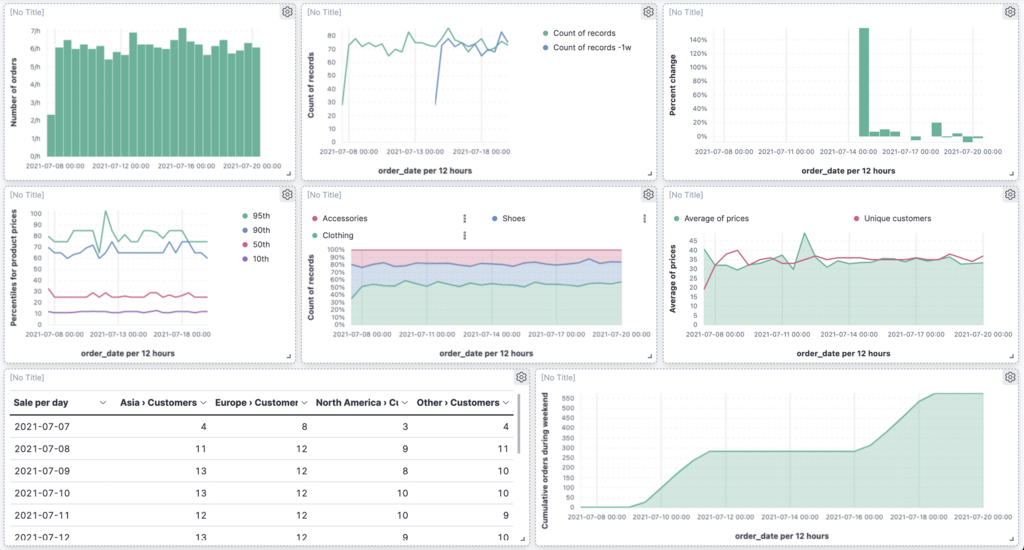
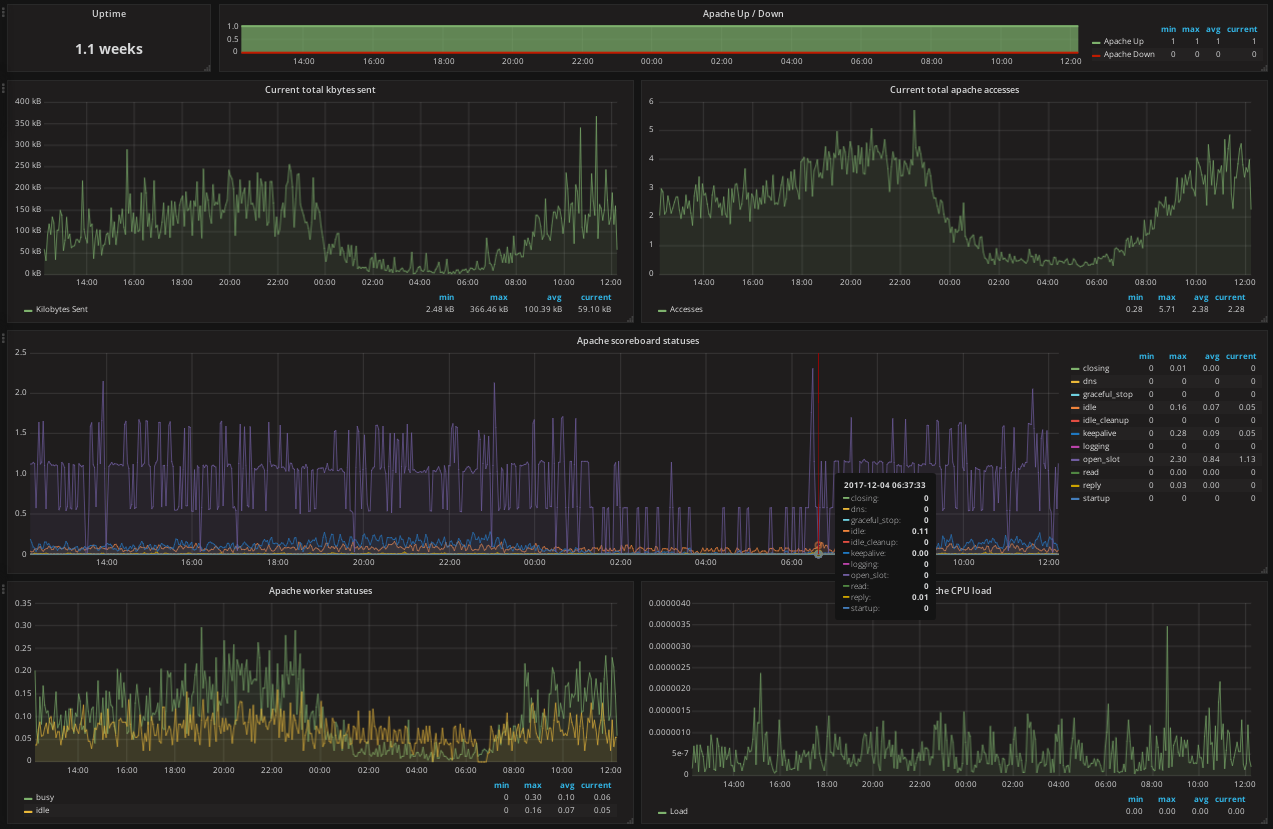
Grafana (Graphite, InfluxDB, OpenTSDB, Prometheus…)
Initially fork of Kibana
Dashboard creation platform https://plotly.com/dash/
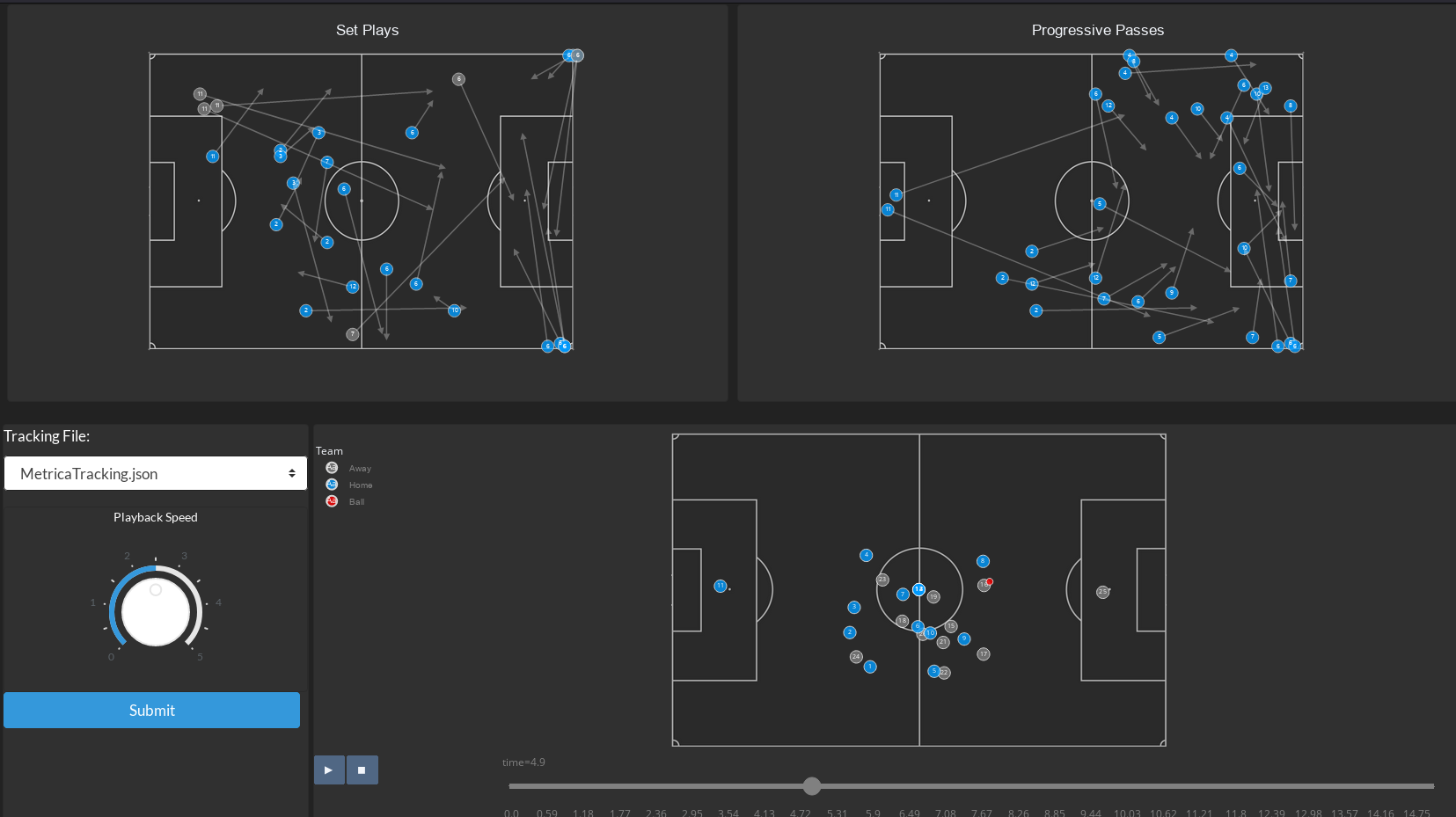
For instance soccer game viz
Example dynamic visualization: NBA Data visualisation (Source)
For reference/inspiration - Timeviz Browser: https://browser.timeviz.net/
ObservableHQ notebooks on Time Series viz
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}